Hashtables
Data requires a number of ways in which it can be stored and accessed. One of the most important implementations includes Hash Tables. In Python, these Hash tables are implemented through the built-in data type i.e, dictionary. In this article, you will learn what are Hash Tables and Hashmaps in Python and how you can implement them using dictionaries
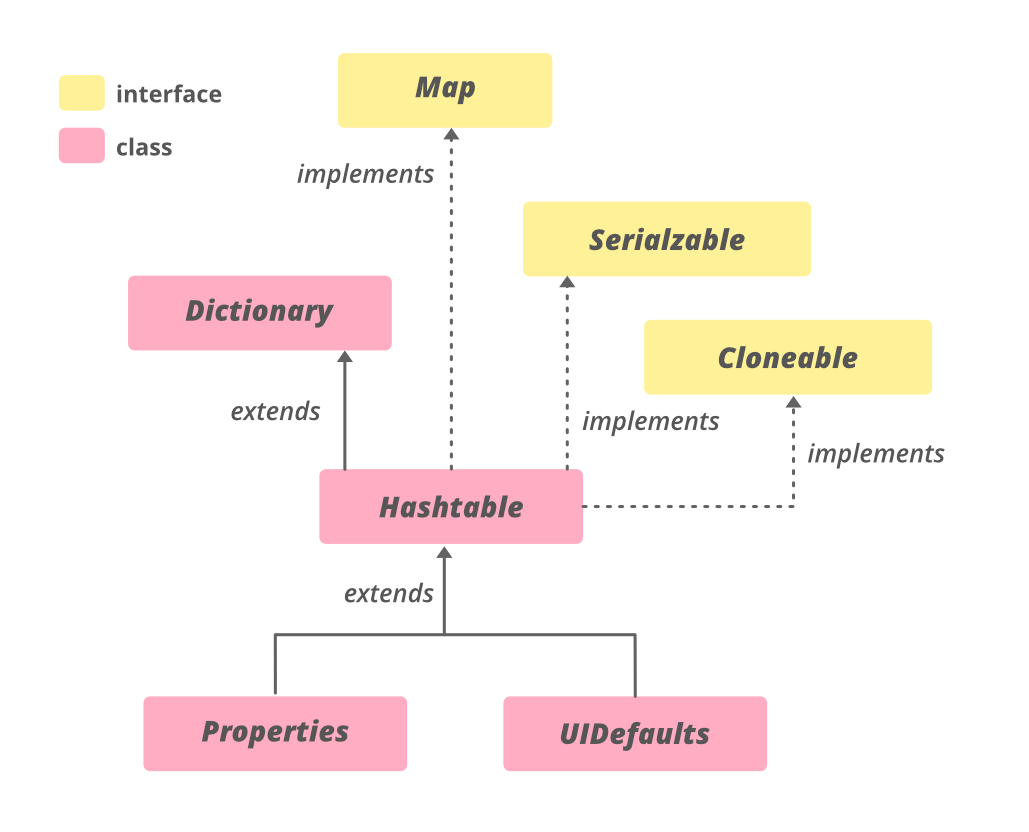
What is a Hashtable? The Hashtable class implements a hash table, which maps keys to values. Any non-null object can be used as a key or as a value. To successfully store and retrieve objects from a hashtable, the objects used as keys must implement the hashCode method and the equals method.
In computer science, a Hash table or a Hashmap is a type of data structure that maps keys to its value pairs (implement abstract array data types). It basically makes use of a function that computes an index value that in turn holds the elements to be searched, inserted, removed, etc. This makes it easy and fast to access data. In general, hash tables store key-value pairs and the key is generated using a hash function.
Hash tables or has maps in Python are implemented through the built-in dictionary data type. The keys of a dictionary in Python are generated by a hashing function. The elements of a dictionary are not ordered and they can be changed.
An example of a dictionary can be a mapping of employee names and their employee IDs or the names of students along with their student IDs.

Hash Table vs hashmap: Difference between Hash Table and Hashmap in Python
Hash Table Synchronized Fast Allows one null key and more than one null values
Hashmap: Non-Synchronized Slow Does not allows null keys or values
Hash Tables: Implementation
Arrays with String Indexes First, let’s consider the nature of a hash table. One way to look at it is that hash tables are like arrays, but each element is referred to not with an integer index, but with a key of type string (generally).
With the array (list), we access the value ‘roja’ with: spanishWords[1]
With the hash table, we refer to ‘roja’ using the key ‘red’:spanishHash[‘red’]
We implement a hash table with two classes. The class KeyValue will represent each entry of the hash table, and the class HashTable will represent the hash table itself.
class KeyValue:
def __init__(self,key,value):
self.key=key
self.value=value
class HashTable:
TABLESIZE=20
def __init__(self)
self.list=[0]*self.TABLESIZE
def get(self,key):
# ....
def set(self,key,value):
# ...
The HashTable class provides methods to put something in (set), and to get something out (get). You’d call these functions like this:
hashTable= HashTable()
hashTable.set("hello","hola")
print hashTable.get("hello") # should print 'hola'
Brute-Force Algorithm
The brute force method for setting entries is this: class HashTable: … set(self,key,value): # create a new KeyValue object # append to the end of the list
get(self,key)
# loop through the list looking for key.
# when you find it, return it.
Instructor Demo: code this
For this algorithm, what is the Big-O efficiency of the get method?
The Magical Hash Function
We can improve our efficiency dramatically by converting each key coming in to an integer index, then placing the new entry using the index.
Here’s how Wikipedia describes it:
In computer science, a hash table, or a hash map, is a data structure that associates keys with values. The primary operation it supports efficiently is a lookup: given a key (e.g. a person’s name), find the corresponding value (e.g. that person’s telephone number). It works by transforming the key using a hash function into a hash, a number that is used as an index in an array to locate the desired location (“bucket”) where the values should be.
For the moment, let’s now worry about how the hash function works and just use an imaginary one. Our algorithm for set and get are now:
set(self,key,value):
# create a new KeyValue object
# call hash(key) to get an integer index.
# put the new KeyValue pair at the indexth place in the list
get(self,key)
# call hash(key) to get an index
# return self.list(index)
def hash(self,key):
# return an index based on the key
How does this improve our efficiency?
What is missing from our algorithm?
Hash Function
def hash(self,key):
# loop through the characters of the key
# convert the character to a number (use ord(c))
# add this number to running total
# return (total modulo sizeOfHashTable) modulo is '%' in Python.
Given this algorithm, what would be returned for a key of “red”? What about “edr”? (hint: the ASCII number for ‘a’ is 97) Dealing with Collisions: Buckets
Since more than one key can return the same integer index, we need to deal with such cases. Our internal list needs to be a list of lists instead of a list of single-string values. We say that our internal list is a list of buckets, where each bucket holds all the key-value pairs that map to a particular index.
To implement, when we place a new key-value pair, we append it to the bucket (list) at the index:
set(self,key,value):
# create a new KeyValue object
# call hash(key) to get an integer index.
# append KeyValue pair into the bucket at the indexth place in the list
To get a value, we must search through the bucket at the index. get(self,key) # call hash(key) to get an index # loop through key-value pairs at the bucket, looking for key
Summary
The hash table is interesting from an algorithms viewpoint because it replaces an O(n) algorithm for searching through keys with an O(1) algorithm that is not based on the data size. Note, however, if you have a bad hash function or not enough buckets, the efficiency moves toward O(n).